

Meet the Social Side of Your Codebase
by Adam Tornhill, April 2015

Let’s face it — programming is hard. You could spend an entire career isolated in a single programming language and still be left with more to learn about it. And as if technology alone weren’t challenging enough, software development is also a social activity. That means software development is prone to the same social biases that you meet in real life. We face the challenges of collaboration, communication, and team work.
If you ever struggled with these issues, this article is for you. If you haven’t, this article is even more relevant: The organizational problems that we’ll discuss are often misinterpreted as technical issues. So follow along, learn to spot them, react, and improve.
Know Your True Bottlenecks
Some years ago I did some work for a large organization. We were close to 200 programmers working on the same system. On my first day, I got assigned to a number of tasks. Perfect! Motivated and eager to get things done, I jumped right in on the code.
I soon noticed that the first task required a change to an
API. It was a simple, tiny change. The problem was just that
this API was owned by a different team. Well, I filed a change
request and walked over to their team lead. Easy,
he said.
This is a simple change. I’ll do it right away.
So I went
back to my desk and started on the next task. And let me tell
you: that was good because it took one whole week to get that
“simple” change done!
I didn’t think much about it. But it turned out that we had to modify that shared API a lot. Every time we did, the change took at least one week. Finally I just had to find out what was going on — how could a simple change take a week? At the next opportunity, I asked the lead on the other team. As it turned out, in order to do the proposed change, he had to modify another API that was owned by a different team. And that team, in turn, had to go to yet another team which, in turn, had the unfortunate position of trying to convince the database administrators to push a change.
No matter how agile we wanted to be, this was the very opposite end of that spectrum. A simple change rippled through the whole organization and took ages to complete. If a simple change like that is expensive, what will happen to larger and more intricate design changes? That’s right — they’ll wreak havoc on the product budget and probably our codebase and sanity too. You don’t want that, so let’s understand the root causes and see how you can prevent them.
Understand the Intersection between People and Code
In the story I just told, the problem wasn’t the design of the software, which was quite sound. The problem was an organization that didn’t fit the way the system was designed.
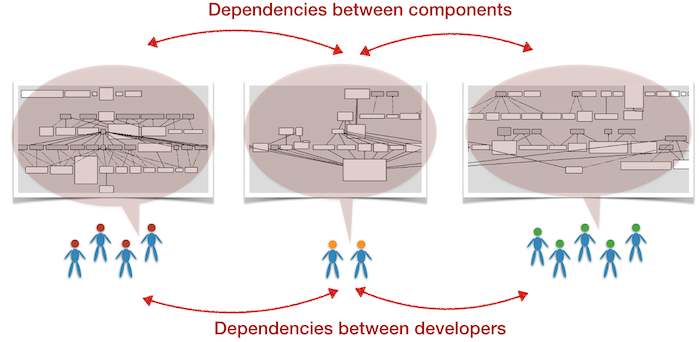
When we have a software system whose different components depend upon each other and those components are developed by different programmers, well, we have a dependency between people too. That alone is tricky. The moment you add teams to the equation, such dependencies turn into true productivity bottlenecks accompanied by the sounds of frustration and miscommunication.
Such misalignments between organization and architecture are common. Worse, we often fail to recognize those problems for what they are. When things go wrong in that space, we usually attribute it to technical issues when, in reality, it’s a discrepancy between the way we’re organized versus the kind of work our codebase supports. These kind of problems are more severe since they impact multiple teams and it’s rare that someone has a holistic picture. As such, the root cause often goes undetected. That means we need to approach these issues differently. We need to look beyond code.
Revisit Conway’s Law
This common problem of an organization that’s misaligned with its software architecture isn’t new. It has haunted the software industry for decades. In fact, it takes us all the way back to the 60’s to a famous observation about software: Conway’s Law. Conway’s Law basically claims that the way we’re organized will be mirrored in the software we design; Our communication structure will be reflected in the code we write.
Conway’s Law has received a lot of attention over the past years, and there are just as many interpretations of it as there are research papers about it. To me, the most interesting interpretation is Conway’s Law in reverse. Here we start with the system we’re building: given a proposed software architecture, what’s the optimal organization to develop it efficiently?
When interpreted in reverse like that, Conway’s Law becomes a useful organizational tool. But, most of the time we aren’t designing new architectures. We have existing systems that we keep maintaining, improving, and adding new features to. We’re constrained by our existing architecture. How can we use Conway’s Law on existing code?
Let Conway’s Law Guide You on Legacy Systems
To apply Conway’s Law to legacy code, your first step is to understand the current state of your system. You need to know how well your codebase supports the way you work with it today. It’s a tricky problem — we probably don’t know what our optimal organization should look like. The good news is that your code knows. Or, more precisely, its history knows.
Yes, I’m referring to your version-control data. Your version-control system keeps a detailed log of all your interactions with the codebase. That history knows which developers contributed, where they crossed paths, and how close to each other in time they came by. It’s all social information — we’re just not used to thinking about version-control data in that way. That means we can mine our source code repositories to uncover hidden communication structures. Let’s see how that looks.
Uncover Hidden Communication Paths
According to Conway, a design effort should be organized
according to the need for communication.
This gives us a good
starting point when reasoning about legacy systems. Conway’s
observation implies that any developers who work in the same
parts of the code need to have good communication paths. That
is, if they work with the same parts of the system, the
developers should also be close from an organizational point
of view.
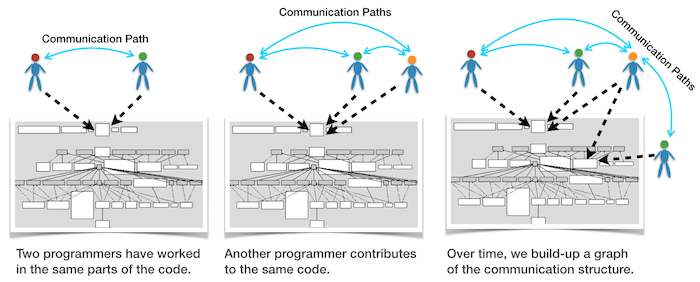
As you see in the figure above, we follow a simple recipe. We scan the source code repository and identify developers who worked on the same modules:
- Every time two programmers have contributed to the same module, these developers get a communication link between them.
- If another programmer contributes to the same code, she gets a communication link as well.
- The more two programmers work in the same parts of the code, the stronger their link.
Once you’ve scanned the source code repository, you’ll have a complete graph over the ideal communication paths in your organization. Note the emphasis on ideal here; These communication paths just show what should have been. There’s no guarantee that these communication paths exist in the real world. That’s where you come in.
Now that you have a picture over the ideal communication paths, you want to compare that information to your real, formal organization. Any discrepancies are a signal that you may have a problem. So let’s have a look at what you might find.
Know the Communication Paths Your Code Wants
In the best of all worlds, you’ll be close to what Conway recommended. Have a look at the following figure. It shows one example of an ideal communication diagram:
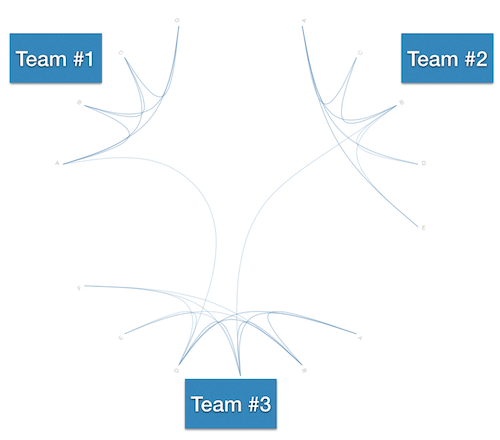
The example in the figure above illustrates three teams. You see that most of the communication paths go between members of the same teams. That’s a good sign. Let’s discuss why.
Remember that a communication diagram is built from the evolution of your codebase. When most paths are between members on the same team, that means the team members work on the same parts of the code. Everyone on such a team has a shared context, which makes communication easier.
As you see in the picture above, there’s the occasional developer who contributes to code that another team works on (note the paths that go between teams). There may be different reasons for those paths. Perhaps they’re hinting at some component that’s shared between teams. Or perhaps it’s a sign of knowledge spread: while cohesive teams are important, it may be useful to rotate team members every now and them. Cross-pollination is good for software teams too. It often breeds knowledge.
The figure above paints a wonderful world. A world of shared context with cohesive teams where we can code away on our tasks without getting in each other’s way. It’s the kind of communication structure you want.
However, if you haven’t paid careful attention to your architecture and its social structures you won’t get there. So let’s look at the opposite side of the spectrum. Let’s look at a disaster so that you know what to avoid.
A Man-month is Still Mythical
About the same time as I started to develop the communication diagrams, I got in contact with an organization in trouble. I was allowed to share the story with you, so read on — what follows is an experience born in organizational pain.
The trouble I met at that organization was a bit surprising since that company had started out in a good position. The company had set out to build a new product. And they were in a good position because they had done something very similar in the past. So they knew that the work would take approximately one year.
A software project that’s predictable? I know — crazy, but it almost happened. Then someone realized that there was this cool trade-show coming up in just three months. Of course, they wanted the product ready by then. Now, how do you take something you know takes a year and compress it down to just three months? Easy — just throw four times as many developers at it.
So they did.
The project was fast-paced. The initial architecture was already set. And in shorter time than it would take to read The Mythical Man-Month, 25 developers were recruited to the project. The company chose to organize the developers in four different teams.
What do you think the communication paths looked like on this project? Well, here they are:
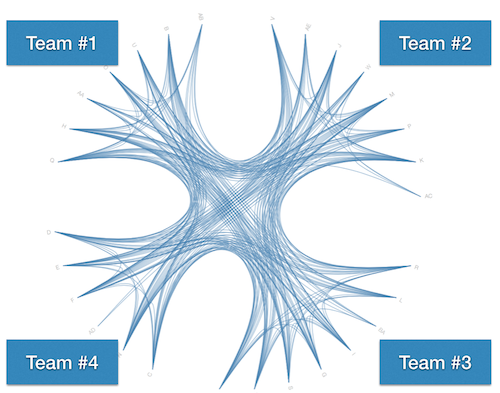
It’s a cool-looking figure, we have to agree on that. But let me assure you: there’s nothing cool about it in practice. What you see is chaos. Complete chaos. The picture above doesn’t really show four teams. What you see is that in practice there was one giant team of 29 developers with artificial organizational boundaries between them. This is a system where every developer works in every part of the codebase — communication paths cross and there’s no shared context within any team. The scene was set for a disaster.
Learn from the Post-mortem Analysis
I didn’t work on the project myself, but I got to analyze the source code repository and talk to some of the developers. Remember that I told you that we tend to miss organizational problems and blame technologies instead? That’s what happened here too.
The developers reported that the code had severe quality problems. In addition, the code was hard to understand. Even if you wrote a piece of code yourself, two days from now it looked completely different since five other developers had worked on it in the meantime.
Finally, the project reported a lot of issues with merge conflicts. Every time a feature branch had to be merged, the developers spent days just trying to make sense of the resulting conflicts, bugs, and overwritten code. If you look at the communication diagram above you see the explanation. This project didn’t have a merge problem — they had a problem that their architecture just couldn’t support their way of working with it.
Of course, that trade show that had been the goal for the development project came and went by without any product to exhibit. Worse, the project wasn’t even done within the originally realistic time frame of one year. The project took more than two years to complete and suffered a long trail of quality problems in the process.
Simplify Communication by Knowledge Maps
When you find signs of the same troubles as the company we just discussed, there are really just two things you can do:
- Change your architecture to support your way of working with it.
- Adapt your organization to fit the way your architecture looks.
Before you go down either path you need to drill deeper though. You need to understand the challenges of the current system. To do that efficiently, you need a knowledge map.
Build a Knowledge Map of Your System
In Your Code as a Crime Scene, we develop several techniques that help us communicate more efficiently on software projects. My personal favorite is a technique I call Knowledge Maps.
A knowledge map shows the distribution of knowledge by developer in a given codebase. The information is, once again, mined from our source code repositories. Here’s an example of how it looks:

In the figure above, each developer is assigned a color. We then measure the contributions of each developer. The one who has contributed most of the code to each module becomes its knowledge owner. You see, each colored circle in the figure above represents a design element (a module, class, or file).
You use a knowledge map as a guide. For example, the map above shows the knowledge distribution in the Scala compiler. Say you join that project and want to find out about the Backend component in the upper right corner. Your map immediately guides you to the light blue developer (the light blue developer owns most of the circles that represent modules in the backend part). And if she doesn’t know, it’s a fairly good guess the green developer knows.
Knowledge maps are based on heuristics that work surprisingly well in practice. Remember the story I told you where a simple change took a week since the affected code was shared between different teams? In that case there were probably at least 10 different developers involved. Knowledge maps solve the problem by pointing you to the right person to talk to. Remember — one of the hardest problems with communication is to know who to communicate with.
Scale the Knowledge Map to Teams
Now that we have a way of identifying the individual knowledge owners, let’s scale it to a team level. By aggregating individual contributions into teams, you’re able to view the knowledge distribution on an organizational level. As a bonus, we get the data we need to evaluate a system with respect to Conway’s Law. How cool is that?
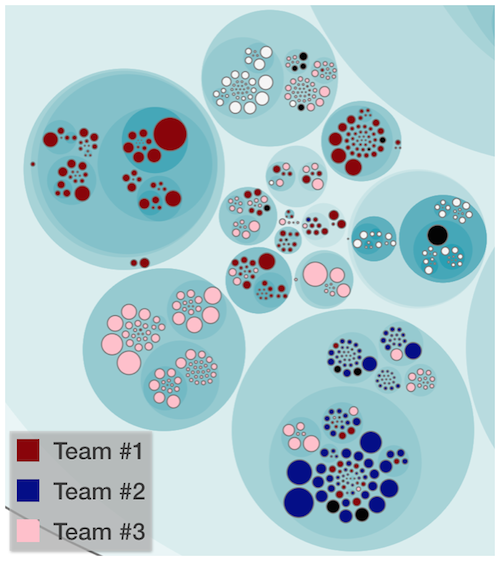
From the perspective of Conway, the map above looks pretty good. We have three different teams working on the codebase. As you see, the Red team have their own sub-system. The same goes for the Pink team (yes, I do as the mob boss Joe in Reservoir Dogs and just assign the colors). Both of these teams show an alignment with the architecture of the system.
But have a look at the component in the lower right corner. You see a fairly large sub-system with contributions from all three teams. When you find something like that you need to investigate the reasons. Perhaps your organization lacks a team to take on the responsibility of that sub-system? More likely, you’ll find that code changes for a reason: If three different teams have to work on the same part, well, that means the code probably has three different reasons to change. Separating it into three distinct components may just be the right thing to do as it allows you to decouple the teams.
Identify Expensive Change Patterns
Mapping out the knowledge distribution in your codebase is one of the most valuable analyses in the social arsenal. But there’s more to it. What if you could use that information to highlight expensive change patterns? That is, change patterns that ripple through parts of the code owned by different teams. Here’s how it looks:
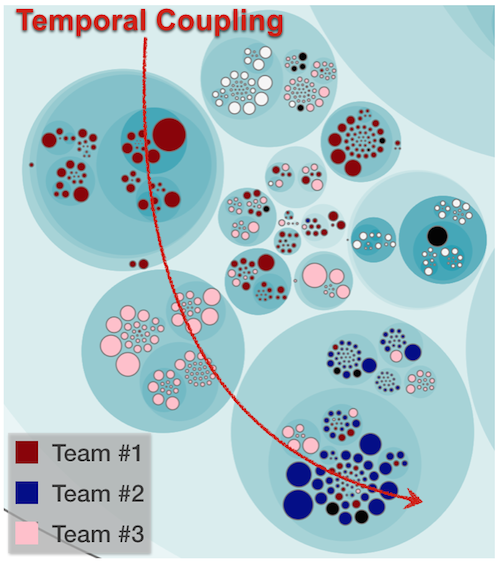
The picture above highlights a modification trend that impacts all three teams. Where does the data come from? Well, again we turn to our digital oracle: version-control data.
There’s an important reason why I recommend the history of your code rather than the code itself. The reason that dependencies between multiple teams go unnoticed is because those dependencies aren’t visible in the code itself. This will just become even more prevalent as our industry moves toward distributed and loosely coupled software architectures as evidenced by the current micro-services trend.
The measure I propose instead is temporal coupling. Temporal coupling identifies components that change at (approximately) the same time. Since we measure from actual modifications and not from the code itself, temporal coupling gives you a radically different view of the system. As such, the analysis is able to identify components that change together both with and without physical dependencies between them.
Overlaying the results of a temporal coupling analysis with the knowledge map lets you find team productivity bottlenecks. Remember the organization I told you about, the one where a small change took ages? Using this very analysis technique lets you identify cases like that and react on time.
Explore the Evolution
We’re almost through this whirlwind tour of software evolutionary techniques now. Along the way, you’ve seen how to uncover the ideal communication paths in your organization, how to evaluate your architecture from a social perspective, and how you can visualize the knowledge distribution in your codebase.
We also met the concept of temporal coupling. Temporal coupling points to parts of your code that tend to change together. It’s a powerful technique that lets you find true productivity bottlenecks.
As we look beyond the code we see our codebase in a new light. These software evolutionary techniques are here to stay: the information we get from our version-control systems is just too valuable to ignore.
I modestly recommend checking out my new book Your Code as a Crime Scene if you want to dive deeper into this fascinating field. The book covers the details of these techniques, lets you try them hands-on, and witness them in action on real-world codebases. You’ll never look at your code in the same way again.


